大论文构思
说明
根据现有工作和之后想做的工作,构思一下可能要做的大论文结构,目前大致思路有2个。
思路1-对话摘要
###思路描述
根据已有小论文进行拓展形成一篇大论文,在小论文中主要解决的问题主要有两点:
- 如何解决对话摘要中的用户交互问题
- 如何解决对话过程中的主题转换检测问题
用户交互问题(dialogue-act-weight)
对话摘要不同于文本摘要,我们还需要关注用户对话的交互问题,小论文中提出了使用 dialogue act 作为额外的交互信息,dialogue act的表示如下图所示:
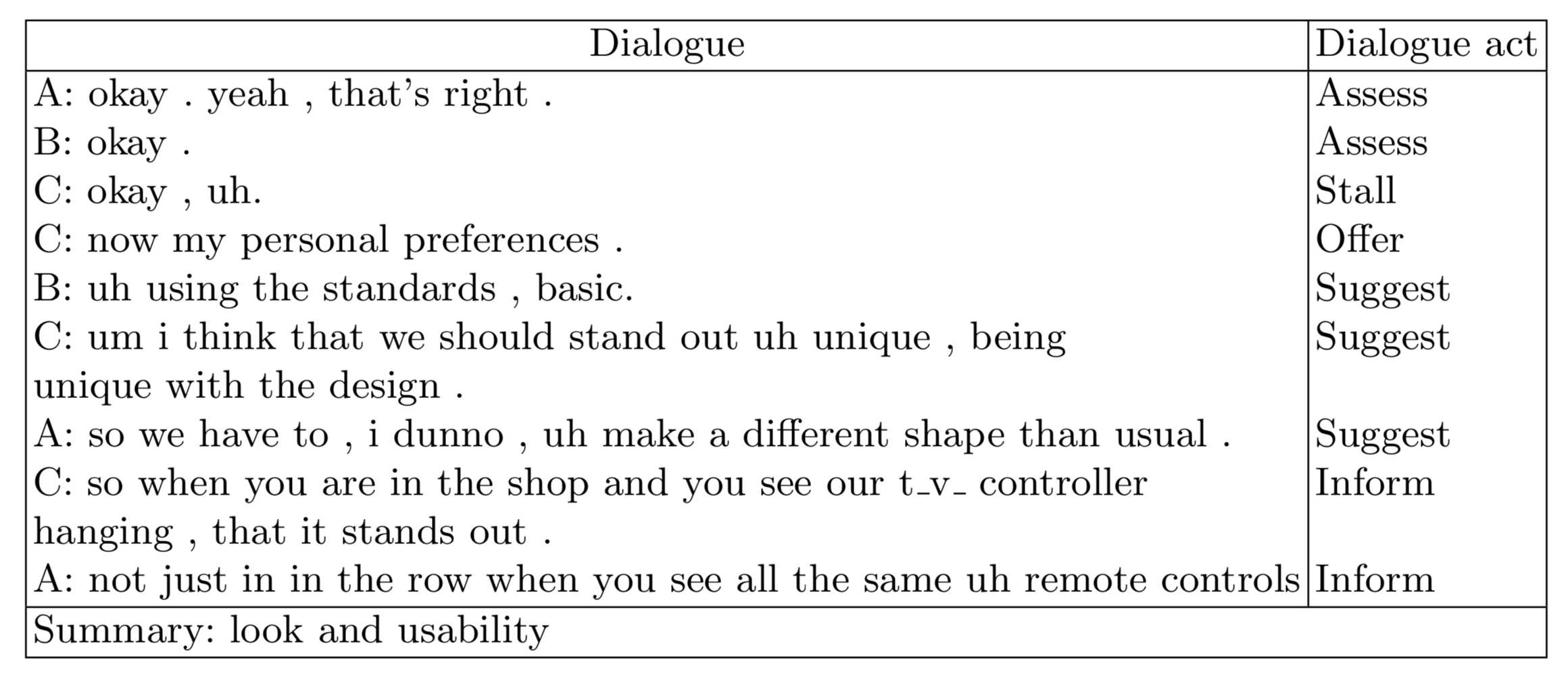
如上图所示,每一句话均有一个 dialogue act 与之对应,因此考虑作为额外信息输入,论文中设计拼接方式为下图所示:
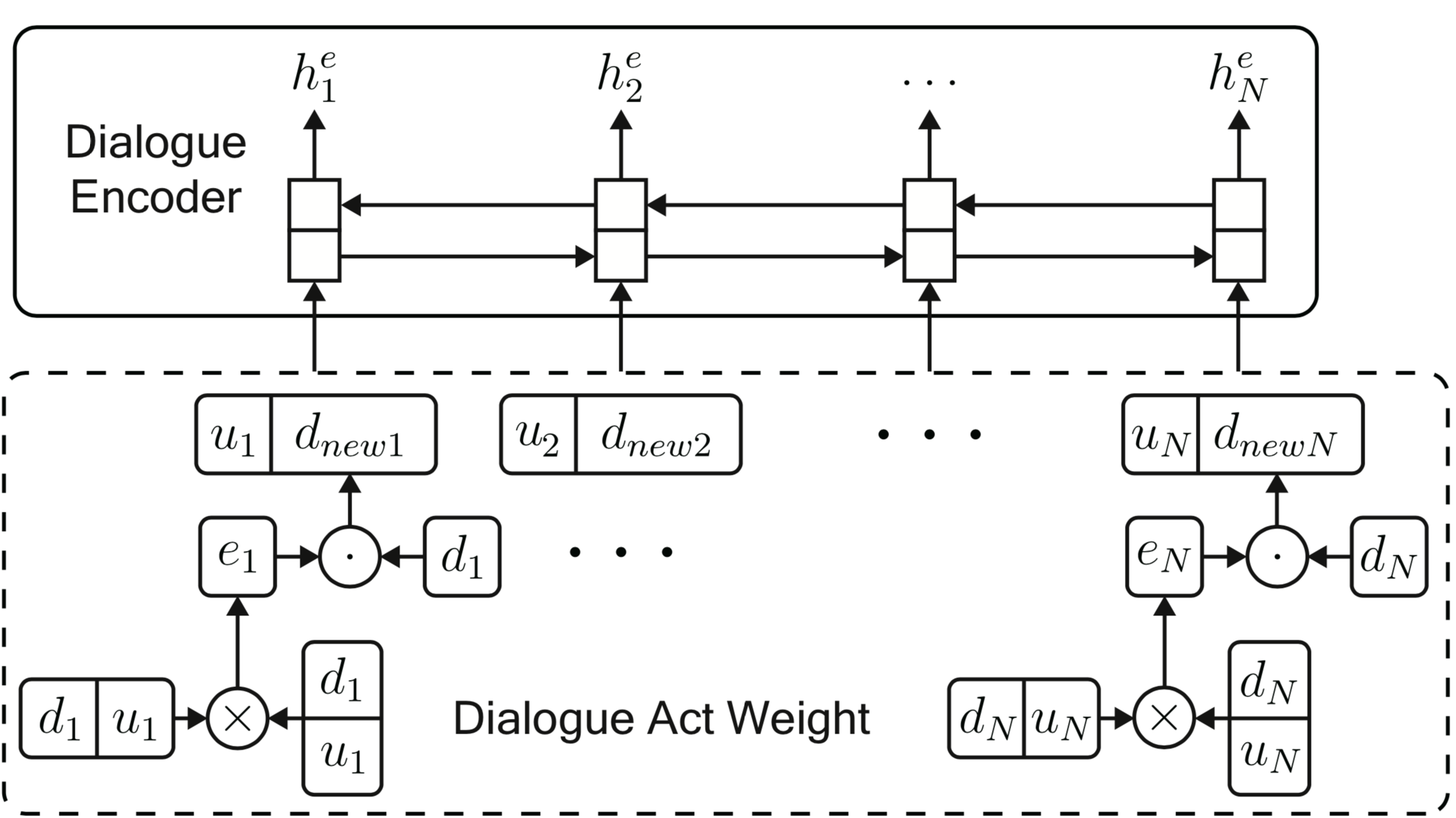
由于同种标签对不同语句所提供的作用是不同的,我们没有直接将dialogue act拼接到dialogue后面,而是通过类似self-attention的方式计算标签权重后,再将每次输入的对话和与对话对应的dialogue act相拼接作为新的输入语句。
其中,dialogue act可以理解为每句话中包含的对话交互信息,它表明了每一句话对全文所起到的作用,比如suggest说明这句话是‘建议’,inform说明这句话包含了主要的‘信息’。
主题转换检测问题(topic-change-info)
一段文本往往只会产生一个主题,而一段对话其实会产生多个主题,本部分考虑添加主题转换信息让模型检测主题转变信息。
在对话中,往往主题转变之前,用户都会说一些转变对话的语句,在英文中 如 ‘uh, ok’,‘let‘s talk about another thing’之类的语句,这类语句如果只考虑全文含义理解,是并不重要的,但是对于我们的主题转变来说,它们恰好是需要我们关注的。
因此我们设计如下结构:
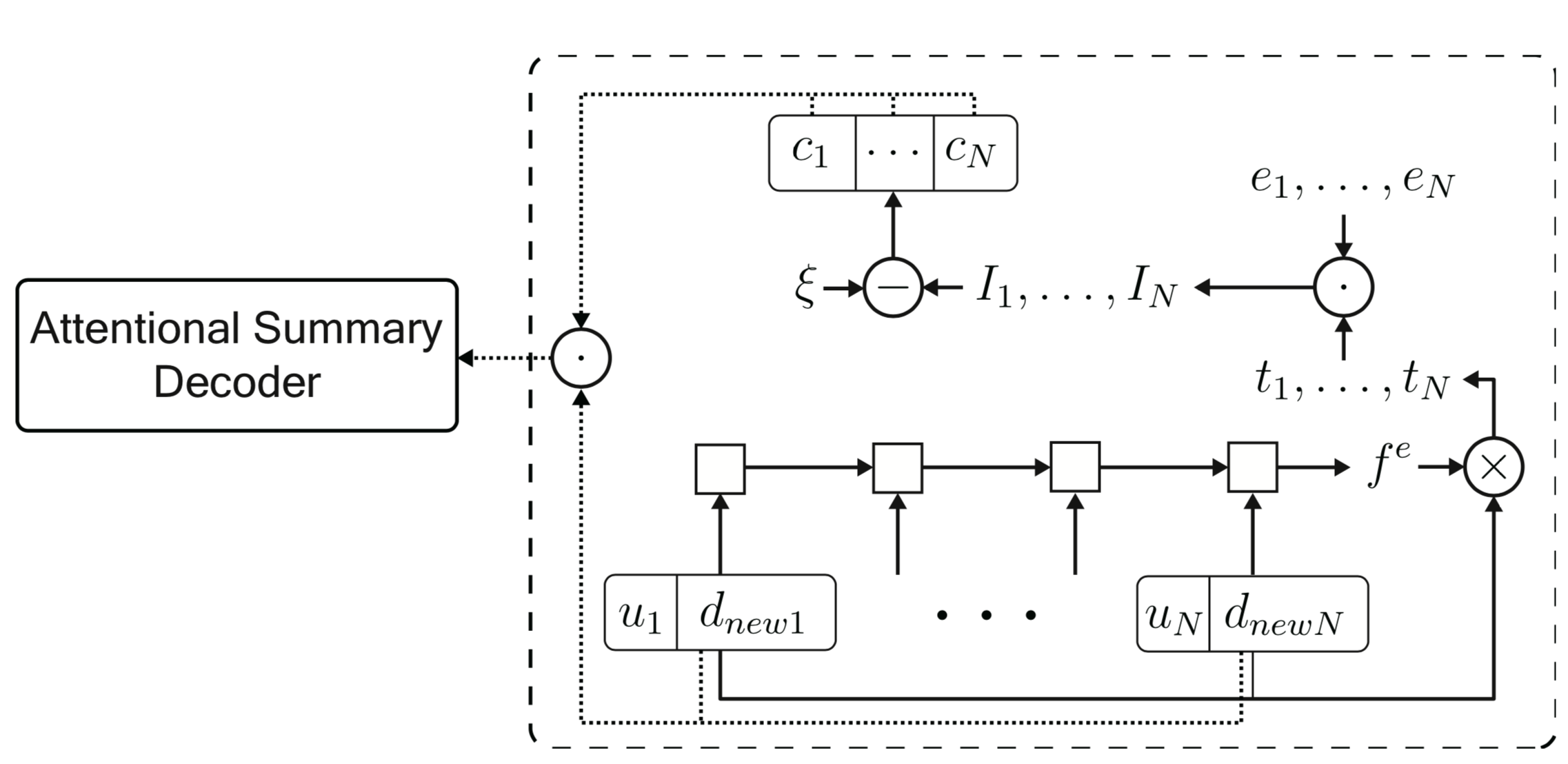
使用单向lstm得到对话的大致信息,每句话与该信息做相似计算得到一个权重,再用该权重与上一节中得到的dialogue act weight组合,得到的就是每句话提供的内容信息重要程度。之后使用减法或除法等方式使模型更关注转折部分,最终在模型解码时添入该部分信息。
sentence-gate模型
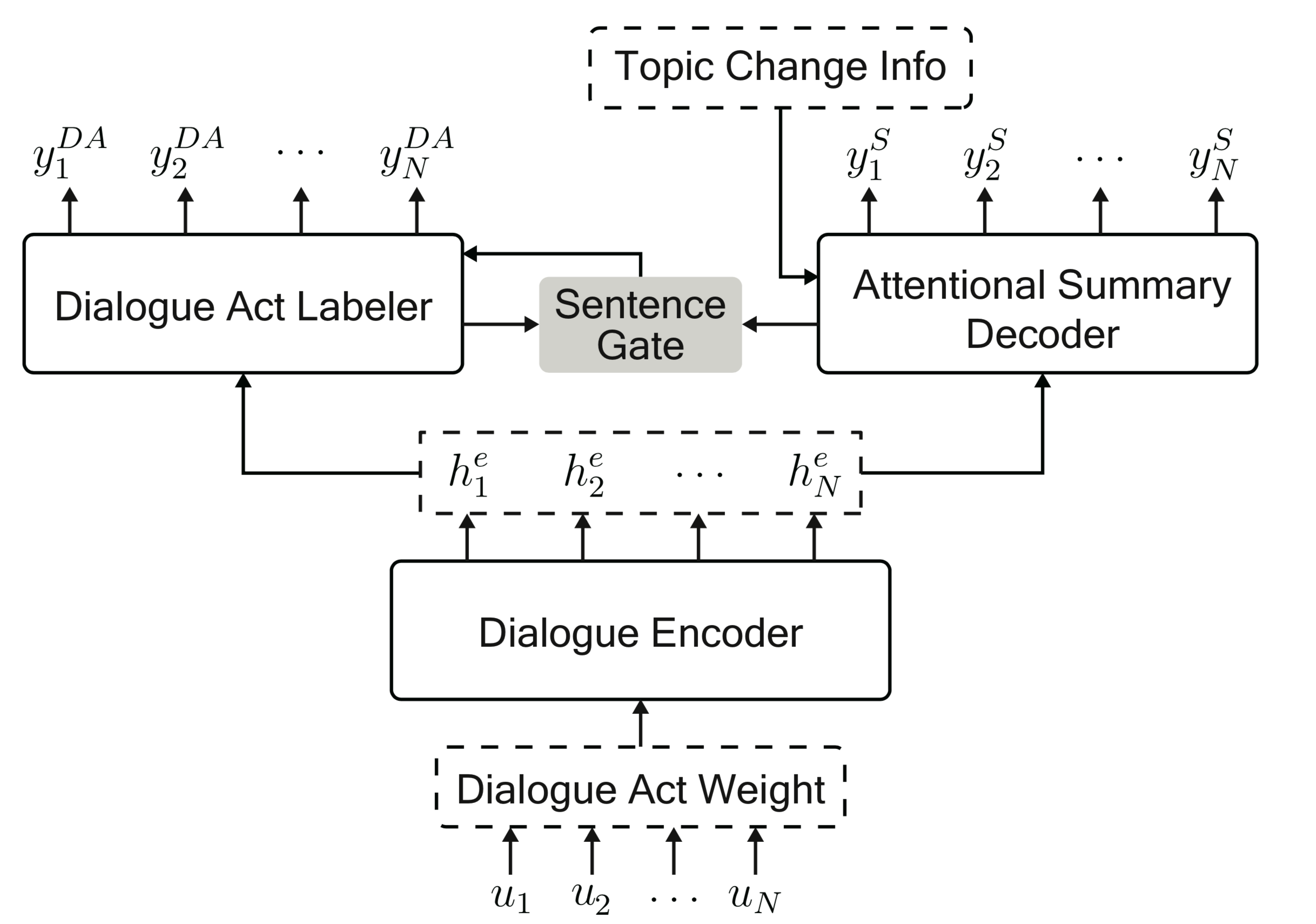
参考论文 “abstractive dialogue summarization with sentence-gated modeling optimized by dialogue act” 中所提到的sentence-gate机制,在解码时同时生成dialogue act 和 summarization,再通过summarization预测dialogue act,提高summarization的准确率。
整体模型
整体模型如下图所示:
思路2-对话摘要与检索式多轮对话
思路描述
检索式多轮对话的主要任务是给出对话和回复,给回复打分。当前的多轮对话中考虑了字和句子两方面粒度,希望能够使用对话摘要生成文本粒度并融入到多轮对话中。该部分还未开始研究
对话摘要生成 文本粒度
这个部分探讨对话摘要的生成,以及探讨对话摘要对多轮对话进行文本粒度的生成,过往的论文中关注了字粒度和句子粒度,但是并没有关注文本粒度,不知道这个想法能否实现。
多轮对话检索
探讨多轮对话检索以及根据对话摘要生成信息,并设计出能够将信息整合至对话检索的模型。